Поскольку центры обработки данных призваны обрабатывать взрыв неструктурированных данных, подаваемых во множество самых современных приложений, будущее для ПЛИС выглядит ярким.
Это потому, что FPGA или программируемые пользователем массивы ворот по существу, микросхемы, которые после программирования могут быть запрограммированы как пользовательские ускорители для рабочих нагрузок, включая машинное обучение, сложный анализ данных, кодирование видео и геномику — приложения, которые имеют далеко идущие последствия для коммуникаций, сетей, здравоохранения, индустрии развлечений и многие другие предприятия.
. Такие приложения предоставляют параллельную обработку, важную особенность FPGA, которая также может быть переконфигурирована «на лету» для обработки новых функций по мере развития характера этих рабочих нагрузок.
Теперь Xilinx, который на протяжении десятилетий соперничал с Altera (теперь частью Intel) за техническое лидерство в FPGA, раскрывает то, что он называет новой категорией продуктов — Adaptiv (19459003)
Содержание статьи
Что такое ACAP?
Первый ряд продуктов в категории имеет кодовое название Эверест, из-за того, что в этом году лента закончилась (завершена ее разработка), а в следующем году она будет поставляться клиентам, сообщает Xilinx в понедельник. Является ли это постепенной эволюцией нынешних FPGA или чем-то более радикальным, трудно сказать, так как компания раскрывает архитектурную модель, которая не содержит многих технических деталей, например, какие именно приложения и процессоры реального времени будут использовать чипы.
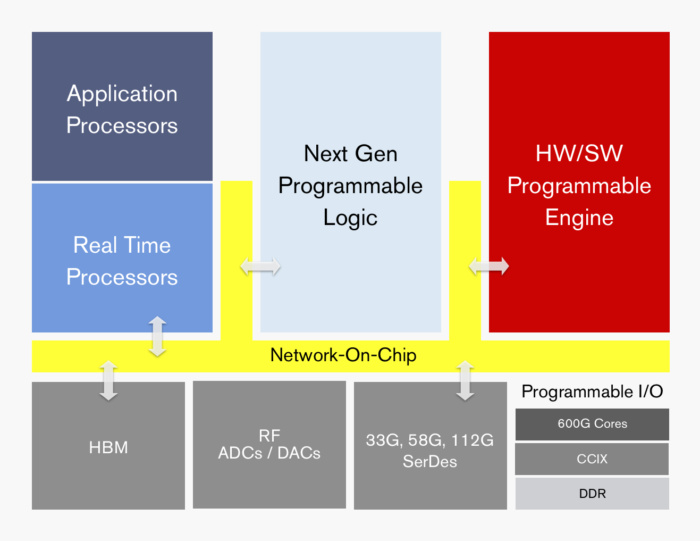
Функции, которые мы действительно знаем, являются косвенными. Everest будет включать в себя стандартную функцию NOC (network-on-a-chip) и использовать соединительную ткань CCIX (Cache Coherent Interconnect for Accelerators), ни одна из которых не отображается в текущих FPGA.
Everest предложит аппаратной и программной программируемости и является одной из первых интегрированных схем на рынке для использования технологии производства 7 нм (в данном случае TSMC).
Несмотря на то, что существуют разногласия по поводу номенклатуры производственного процесса и относительных достоинств производственных процессов Intel и TSMC, основная проблема, связанная с технологией производства, тем больше плотность транзисторов на процессорах, что приводит к снижению стоимости и производительности. идея состоит в том, что 7nm составляет примерно половину размера геометрии текущего поколения FPGA, что в четыре раза превышает производительность на квадратный миллиметр. Эверест будет иметь до 50 миллиардов транзисторов, по сравнению с, например, Intel (ранее Altera), текущими Stratix 10 FPGA, которые используют 14-нм производственный процесс и спортивные 30 миллиардов транзисторов.
 Xilinx
Xilinx Первый ассортимент продуктов Xilinx с использованием технологии ACAP под кодовым названием Everest, разработанный в технологической технологии TSMC.
«Мы действительно чувствуем, что это другая категория продуктов», — сказал недавно президент Xilinx Виктор Пэн. В течение последних четырех лет Xilinx потратил около миллиарда долларов, и в проекте было реализовано 1500 инженеров.
Xilinx в настоящее время утверждает, что его FPGA, благодаря их способности настраиваться для разных рабочих нагрузок, ускоряют обработку в 40 раз для машинное обучение, 10 раз для обработки видео и изображений и 100 раз для геномики по сравнению с системами на базе процессоров или графических процессоров. ACAPs, по его словам, будет ускорять ускорение AI-вывода в 20 раз, а связь 5G — в 4 раза по сравнению с его текущей архитектурой FPGA.
FPGA традиционно предлагают массив настраиваемых логических блоков, связанных через программируемые межсоединения. Реконфигурация FPGA в течение многих лет проводилась с помощью языков описания аппаратных средств (HDL), но разработчики чипов начали настраивать архитектуру устройств, чтобы использовать более высокоуровневые языки программирования программного обеспечения.
Недавно выпущенный Xilinx Zynq All Programmable SoC (система на чипе) объединяет программную программируемость процессора на основе ARM, который был интегрирован в продукт, с аппаратной программируемостью FPGA.
«Мы трансформировались, но ACAP — это перегиб если хотите, — сказал Пэн. «Несмотря на то, что раньше FPGA были гибкими и адаптируемыми, уровень этого намного выше, и да, мы начали совсем недавно, чтобы люди могли больше развиваться на уровне программного обеспечения, но степень, в которой мы собираемся сделать это с помощью этого класса продукт намного выше. Это означает, что это квантовый шаг по сравнению с тем, что мы видели раньше ».
Использование высокоуровневых языков программирования
Xilinx говорит, что разработчики программного обеспечения смогут работать с Everest с помощью таких инструментов, как C / C ++, OpenCL и Python. Everest также может программироваться на аппаратном уровне, уровне регистрации (RTL) с использованием инструментов HDL, таких как Verilog и VHDL.
Карл Фрейнд, аналитик Moor Insights & Strategy, считает, что Everest является скорее эволюцией Xilinx's стратегией, а не радикальным шагом, но подчеркивает, что прогресс в аппаратных и программных элементах Эвереста является значительным.
«Это правда, это новая категория, но это не просто чип, который делает его новой категорией — это чип, программное обеспечение, библиотеки и даже модели веб-разработки», — сказал Фрейнд.
«Они много инвестировали в стеки программного обеспечения, так называемые стеки ускорения, которые позволяют быстрее развертывать решения FPGA, потому что они в основном предоставляют некоторые стандартизированные библиотеки, инструменты и алгоритмы и блоки IP, которые вы можете просто подобрать и развертывание на вашем FPGA », — сказал он.
В дополнение к еще не определенному многоядерному SoC (система на чипе) Xlinx говорит, что Everest будет предлагать PCIe, а также поддержку межсоединений CCIX, многомодовый Ethernet-контроллеры, встроенные блоки управления для управления безопасностью и питанием и программируемые интерфейсы ввода-вывода, а также различные типы Serdes-приемопередатчиков, которые преобразуют параллельные данные в последовательные данные и наоборот. В частности, он предложит NRZ 33 Гбит / невозврат t o ноль), 58 Гбит / с PAM-4 (импульсная амплитудная модуляция) и 112G PAM-4 SerDes. Как правило, механизм PAM обладает большей пропускной способностью, чем NRZ.
Некоторые чипы Everest также предлагают высокоскоростную память (HBM) или программируемые АЦП (аналого-цифровые) и ЦАП (цифро-аналоговые) преобразователи , Говорит Xilinx.
Сеть на чипе, когерентный кеш являются ключевыми отличиями
. Xilinx говорит, что ключевым отличием между FPGA и ACAP является NOC, который соединяет различные подсистемы устройства, такие как несколько процессоров и элементы ввода / вывода. До сих пор у ПЛИС не было системных NOC, и разработчикам приходилось по существу создавать инфраструктуру соединения через программируемую логику чипов. «Вы можете запрограммировать подсистемы с помощью программируемой логики, но в целом вы не получите одинаковых характеристик производительности», — сказал Пэн.
Другим ключевым элементом является CCIX. «То, что революционно, — это кеш-когерентный, — сказал Фрейнд. «Впервые вы сможете создать систему с кеш-когерентным ускорителем с использованием стандартного сетевого протокола, и этого сейчас нет в отрасли».
CCIX — это набор спецификаций, разрабатываемых консорциумом CCIX для решения проблемы когерентности кеша или того, как гарантировать, что разные процессоры не сталкиваются при попытке изменить одно и то же пространство памяти или работать с устаревшими копиями данных.
Большой мишень для Эверест — это ИИ. Никто не ожидает, что Everest будет конкурировать с чистыми лошадиными силами за процессорами Intel и графическими процессорами Nvidia, которые используются для «обучения» наборов данных терабайтного размера для работы в мамонтовых, 100-уровневых, машинных обучающих нейронных сетях.
Но адаптивность Эверест, как и традиционные ПЛИС, делает его идеальным для «выведения» или фактически использует нейронные сети в реальных ситуациях, отмечает Фрейнд. Это потому, что каждый уровень нейронной сети должен обрабатываться с наименьшей точностью, чтобы сэкономить время и энергию. В отличие от процессоров с фиксированной точностью, FPGA могут быть запрограммированы для обработки каждого уровня нейронной сети после ее создания с наименьшей точностью, подходящей для этого уровня.
Edge-устройства являются основной целью
. И хотя Xilinx говорит, что его основной целью является центр обработки данных, периферийные устройства и IoT могут в конечном итоге быть там, где светит Everest. [19]
Microsoft, которая была первым крупным провайдером облачных технологий, объявила о развертывании приложений, которые будут использоваться в периферийных устройствах, которые крайне ограничены мощью по сравнению с большими серверами, что делает их идеальными кандидатами для FPGA. FPGA для своей инфраструктуры облачных облачных вычислений, в прошлом году предоставили чипам большую вотум доверия для их использования в ИИ, объявив, что он будет использовать ПЛИС для своей платформы глубокого изучения Project Brainwave. Он использует Stratix 10 FPGA от Nemesis Xilinx, Intel / Altera, но это тем не менее помогает укрепить идею использования FPGA для ИИ.
Продолжающееся соперничество между Xilinx и Intel будет играть, когда компании переходят на более мелкие производства технологической технологии. Intel уже анонсировала FPGA с кодовым названием Falcon Mesa, который будет построен с технологией Intel 10nm для производства, что, по словам некоторых представителей отрасли, обеспечит эквивалентную плотность транзисторов для 7-нм процесса TSMC.
. С Everest и, возможно, Falcon Mesa, выпущенным в 2019 году, похоже, что FPGA — или в случае Xilinx, ACAP — будут играть более важную роль в вычислении тенденций, чем когда-либо.






