
Изображение: Microsoft
Microsoft и Intel недавно совместно работали над новым исследовательским проектом, в котором исследовался новый подход к обнаружению и классификации вредоносных программ.
Вызывается STAMINA ( STA tic M alware). -as- I маг N etwork анализ), проект опирается на новую технику, которая преобразует образцы вредоносных программ в изображения в градациях серого, а затем сканирует изображение для текстурного и структурные шаблоны, характерные для образцов вредоносного ПО.
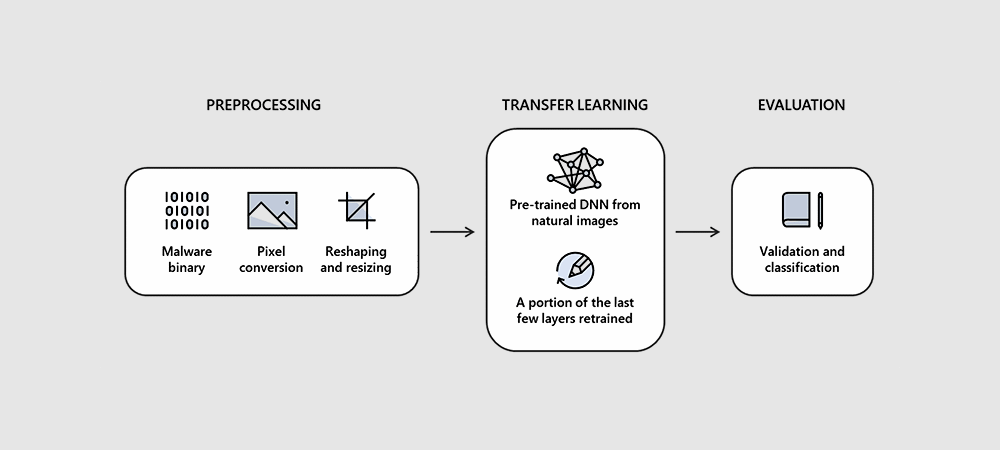
Как на самом деле работает STAMINA
Исследовательская группа Intel-Microsoft заявила, что весь процесс состоит из нескольких простых шагов. Первый состоял в том, чтобы взять входной файл и преобразовать его двоичную форму в поток необработанных данных пикселей.
Затем исследователи взяли этот одномерный (1D) поток пикселей и преобразовали его в 2D-фотографию, чтобы получить нормальное изображение. алгоритмы анализа могут анализировать его.
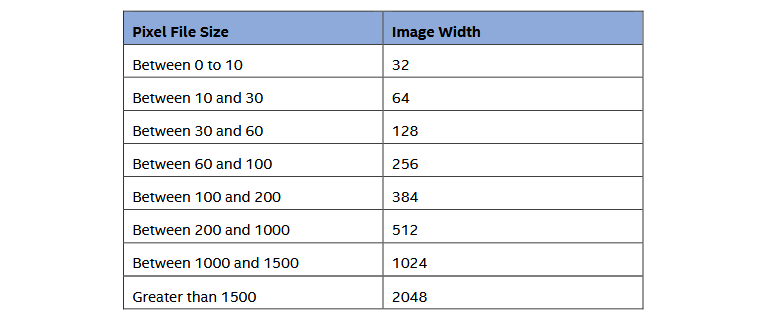
Ширина изображения была выбрана на основе размера входного файла, используя таблицу ниже. Высота была динамической и получалась в результате деления потока необработанных пикселей на выбранное значение ширины.

Изображение: Intel, Microsoft
После объединения необработанного пиксельного потока в нормально выглядящее двухмерное изображение исследователи затем изменили размер получаемой фотографии до меньшего размера.
Команда Intel и Microsoft заявила, что изменение размера необработанного изображения «не оказало негативного влияния». результат классификации ", и это был необходимый шаг, чтобы вычислительные ресурсы не работали с изображениями, состоящими из миллиардов пикселей, что, скорее всего, замедлило бы обработку.
Затем измененные изображения подавались в предварительно обученную глубокую нейронную сеть (DNN), которая сканировала изображение (двумерное представление штамма вредоносного ПО) и классифицировала его как чистое или зараженное.
Microsoft говорит, что предоставил образец из 2,2 миллионов зараженных хэшей PE (Portable Executable), которые послужили основой для исследования.
Исследователи использовали 60% известных образцов вредоносного ПО для обучения оригинальному алгоритму DNN, 20% файлы для проверки DNN и другие 20% для фактического процесса тестирования.
Исследовательская группа заявила, что STAMINA достигла точности 99,07% при выявлении и классификации образцов вредоносного ПО, с уровнем ложных срабатываний 2,58%.
«Результаты, безусловно, стимулируют использование глубокого обучения для целей классификации вредоносных программ», — говорят Джугал Парих и Марк Марино, два исследователя Microsoft, которые участвовали в исследовании от имени Microsoft Threat Protection Intelligen. ce Team.
Инвестиции Microsoft в машинное обучение
Данное исследование является частью недавних усилий Microsoft по улучшению обнаружения вредоносных программ с помощью методов машинного обучения.
STAMINA использовала метод, называемый глубоким обучением , Глубокое обучение — это подмножество машинного обучения (ML), ветви искусственного интеллекта (AI), которая относится к интеллектуальным компьютерным сетям, которые способны самостоятельно обучаться на основе входных данных, хранящихся в неструктурированном или немаркированном формате. в данном случае это случайный вредоносный двоичный файл.
Microsoft сказала, что, хотя STAMINA была точной и быстрой при работе с файлами меньшего размера, она ошибалась с более крупными.
«Для приложений большего размера STAMINA становится меньше эффективен из-за ограничений в преобразовании миллиардов пикселей в изображения JPEG и последующем изменении их размера », — говорится в сообщении Microsoft на прошлой неделе в своем блоге.
Однако, скорее всего, это не имеет значения, поскольку проект можно использовать для Только небольшие файлы, с отличными результатами.
В интервью ZDNet в начале этого месяца Танмай Ганачарья, директор по исследованиям безопасности Microsoft Threat Protection, сказал, что Microsoft в настоящее время в значительной степени полагается на машинное обучение для обнаружения. Это связано с возникающими угрозами, и эта система использует различные модули машинного обучения, которые развертываются на системах клиентов или серверах Microsoft.
В настоящее время Microsoft использует механизмы модели машинного обучения на стороне клиента, модели машинного обучения на стороне облака, машины По словам Ганачарьи, учебные модули для захвата последовательностей поведения или захвата содержимого самого файла.
Основываясь на полученных результатах, STAMINA вполне может быть одним из тех модулей ML, которые мы вскоре увидим, реализованными в Microsoft как способ обнаружить вредоносное ПО.
В настоящее время Microsoft может заставить этот подход работать лучше, чем другие компании, в первую очередь благодаря простым данным, которые она имеет из сотен миллионов установок Защитника Windows.
«Любой может построить модель, но помеченные данные, их количество и качество действительно помогают надлежащим образом обучить модели машинного обучения и, следовательно, определяют, насколько они эффективны. быть », — сказал Ганачарья.
« И у нас, в Microsoft, это преимущество, потому что у нас есть датчики, которые передают нам много интересных сигналов через электронную почту, идентификацию, конечную точку и возможность объединить их. "






